Midv-250 Info
The MIDV-250: A Technological Leap in Automatic Identification
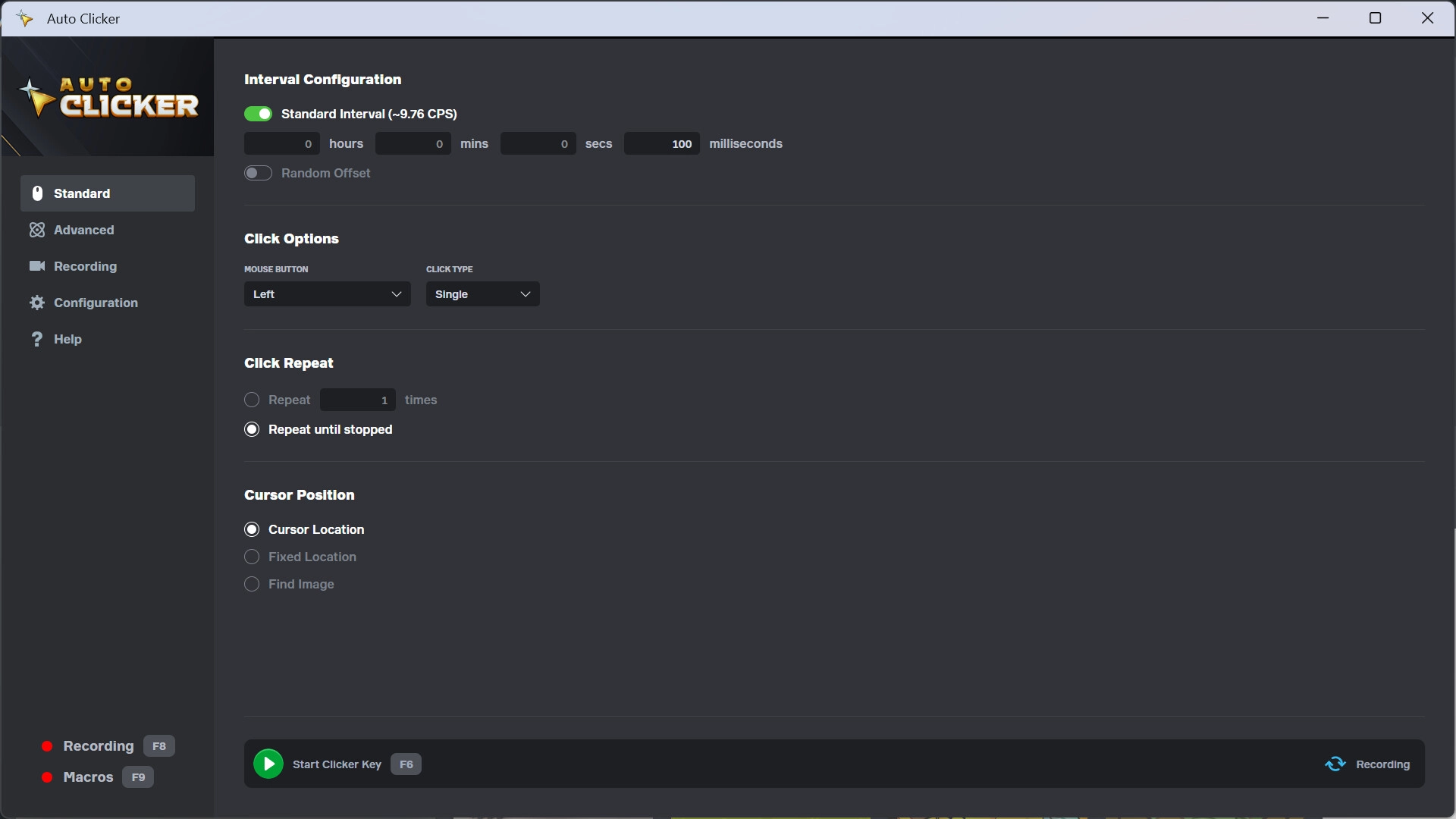
The MIDV-250, a cutting-edge innovation in the realm of automatic identification and data capture, has revolutionized the way industries approach identification and data processing. This remarkable technology has been engineered to provide efficient, accurate, and high-speed identification solutions, catering to a wide range of applications across various sectors.
At its core, the MIDV-250 is designed to read and decode a multitude of identification formats, including barcodes, RFID tags, and other data carriers. This versatility allows it to seamlessly integrate into diverse operational environments, enhancing the capability of businesses to manage and process data with unprecedented precision and speed.
One of the pivotal features of the MIDV-250 is its exceptional reading accuracy. Equipped with advanced imaging technology and sophisticated algorithms, it can decode even the most challenging codes with a high degree of reliability. This not only reduces the rate of false reads but also minimizes the need for manual intervention, thereby streamlining workflows and boosting productivity.
Moreover, the MIDV-250 is characterized by its robustness and adaptability. Constructed to withstand the rigors of industrial environments, it operates flawlessly under a wide range of conditions, from extreme temperatures to varying lighting scenarios. This resilience ensures that it can be deployed in settings that would typically pose challenges to less durable devices, making it an invaluable asset for sectors such as logistics, manufacturing, and healthcare.
The implications of the MIDV-250's capabilities extend beyond mere operational efficiency. By providing real-time data capture and processing, it enables businesses to make informed decisions more swiftly, enhancing their responsiveness to dynamic market conditions. Furthermore, its integration with existing systems and software is remarkably straightforward, facilitating a hassle-free implementation process that minimizes downtime and accelerates the realization of benefits.
The MIDV-250 also stands out for its scalability. Whether it's a small enterprise looking to upgrade its identification systems or a large corporation aiming to overhaul its data capture infrastructure, this technology can be tailored to meet specific needs. Its modular design allows for easy upgrades and adaptations, ensuring that it remains a valuable tool as businesses evolve and grow.
In conclusion, the MIDV-250 represents a significant advancement in the field of automatic identification and data capture. Its combination of accuracy, speed, versatility, and resilience makes it an indispensable tool for businesses seeking to optimize their operations and data management processes. As industries continue to navigate the complexities of the modern marketplace, technologies like the MIDV-250 will play a crucial role in shaping their success and competitiveness.
The MIDV-250 (Mobile Identity Document Video 250) is a specialized benchmark dataset designed for the development and evaluation of computer vision algorithms used in identity document analysis and recognition.
Created by researchers at Smart Engines and other academic institutions, this dataset is part of the larger MIDV family, which includes MIDV-500, MIDV-2019, and MIDV-2020. It specifically addresses the challenges of recognizing documents in real-world conditions, such as those captured by mobile device cameras. Understanding the MIDV Ecosystem
The MIDV series was born out of a critical need for open-source data in the field of document analysis. Because real identity documents contain sensitive personal information (PII), researchers often struggle to find large-scale, publicly available datasets for training and testing. The MIDV datasets solve this by using "mock" documents that either belong to the public domain or are synthetically generated to mimic real-world IDs without exposing actual people's data.
MIDV-250! That's an interesting topic. MIDV-250 stands for Middle Infrared Developmental Vehicle, a prototype armored vehicle developed by the Soviet Union in the 1970s.
Here's an informative piece on MIDV-250:
Introduction
The MIDV-250 was a experimental armored vehicle designed by the Soviet Union during the Cold War era. The vehicle's development began in the early 1970s, with the primary goal of creating a versatile, multi-role armored platform that could fulfill various tasks on the battlefield.
Design and Features
The MIDV-250 was based on the chassis of the BTR-60 armored personnel carrier (APC). It featured a modified hull with a more powerful engine, improved armor protection, and a range of interchangeable mission modules. The vehicle's design allowed it to be easily reconfigured for different roles, such as:
- Armored personnel carrier (APC)
- Infantry fighting vehicle (IFV)
- Amphibious assault vehicle
- Medical evacuation vehicle
- Cargo transport vehicle
The MIDV-250 was equipped with a 300-hp diesel engine, which provided a top speed of approximately 80 km/h (50 mph) on land and 10 km/h (6.2 mph) in water. The vehicle's armor protection was designed to withstand small arms fire and shell splinters.
Armament and Equipment
The MIDV-250 was armed with a 30mm automatic cannon (2A42) and a 7.62mm machine gun (PKT) coaxially mounted with the cannon. The vehicle's armament was designed to engage and destroy enemy armored vehicles, fortifications, and soft targets.
The MIDV-250 also featured a range of advanced equipment, including:
- A laser rangefinder
- A night vision device
- A communication system with radio and intercom
- A fire suppression system
Development and Testing
The MIDV-250 underwent extensive testing and evaluation in the mid-1970s. The vehicle demonstrated improved mobility, firepower, and versatility compared to existing Soviet armored vehicles. However, the project was ultimately canceled due to the Soviet Union's shifting priorities and the development of other armored vehicle programs, such as the BMP-2 and BTR-80.
Legacy
Although the MIDV-250 did not enter mass production or service with the Soviet military, it represented an important step in the development of modern armored vehicles. The vehicle's design and features influenced the creation of later Soviet and Russian armored platforms, such as the BTR-90 and BMP-3. MIDV-250
The MIDV-250 remains an interesting footnote in the history of armored vehicle development, showcasing the innovative approaches and design philosophies of the Soviet Union during the Cold War era.
Would you like to know more about other armored vehicles or Soviet military projects?
Title: Exploring the Capabilities of MIDV-250
Content: The MIDV-250 is an advanced armored vehicle designed to provide protected mobility for infantry units in various combat environments. With its robust design and versatile capabilities, the MIDV-250 plays a critical role in modern military operations.
-
Key Features:
- Protection: The MIDV-250 offers enhanced protection against ballistic threats, including small arms fire and artillery fragments.
- Mobility: Equipped with a powerful engine, the MIDV-250 ensures high mobility and rapid deployment in challenging terrains.
- Communication: The vehicle features advanced communication systems, enabling seamless coordination between units and command centers.
-
Operational Benefits:
- Enhanced Situational Awareness: The MIDV-250 provides real-time battlefield awareness, allowing commanders to make informed decisions.
- Improved Survivability: The vehicle's protective design and advanced materials minimize the risk of injury or damage.
-
Future Developments:
- The MIDV-250 is expected to undergo continuous upgrades and improvements.
MIDV-250 reflects a significant advancement in military vehicle technology.
Diagnosis and Treatment
- Diagnosis: Laboratory tests, including real-time PCR, serology, and viral isolation, are used to confirm cases.
- Treatment: There are no specific drugs or vaccines approved for human use against Nipah virus infection, though various therapeutic and preventive measures are under research.
Brief example piece (1-page) — contemplative tech note
Title: Reflecting on MIDV-250 — Data, Ethics, and Robustness
The MIDV-250 dataset captures a tension central to modern computer vision: the promise of robust document understanding versus the ethical and privacy questions that accompany datasets built from identity documents. On the technical side, MIDV-250 offers diversity in capture conditions (varying lighting, perspective, noise), comprehensive annotations, and multiple document types, making it a valuable benchmark for tasks such as layout analysis, OCR, and document detection. Models trained and tested on MIDV-250 can learn resilience to real-world distortions—skew, blur, shadows—and provide measurable comparisons across architectures and preprocessing pipelines.
Yet the dataset also provokes reflection. Identity documents are inherently sensitive. Even if MIDV-250 is designed for research and anonymized labels, the domain highlights risks: misuse of high-performing recognition systems for surveillance, identity theft, or discriminatory profiling. Researchers must balance progress with responsibility: applying strict access controls, minimizing retention of raw sensitive images, and prioritizing privacy-preserving techniques (on-device inference, differential privacy, synthetic data augmentation).
Finally, robustness and fairness deserve equal emphasis. Benchmarks like MIDV-250 are only as useful as the scenarios they represent. Future work should expand document diversity across issuers, languages, and demographic variability; incorporate adversarial and occlusion cases; and standardize evaluation of fairness across subgroups. Progress in document understanding should be measured not only by accuracy but by safety, transparency, and alignment with ethical norms.
Conclusion: MIDV-250 is a pragmatic and technically rich resource for advancing document OCR and detection. Its use should be guided by careful ethical considerations, thoughtful dataset handling, and a commitment to developing systems that are robust, fair, and privacy-conscious.
Would you like a short technical summary of MIDV-250 contents (counts, annotations, file formats) or a sample code snippet to load and use it?
Prevention and Control
- General Measures: Avoiding direct contact with bats and pigs, and any surfaces or materials contaminated with the urine, feces, or saliva of these animals.
- Public Health Response: During outbreaks, isolation of patients, use of personal protective equipment, and adequate infection control practices are critical.
Conclusion
The MIDV-250 represents a significant step forward in industrial technology, promising to redefine the boundaries of what is possible in terms of precision, efficiency, and innovation. While the specific details of the MIDV-250 might vary based on its actual application or development, the concept it embodies is crucial for the future of industries worldwide. Embracing such technological advancements is key to achieving sustainable growth and maintaining a competitive edge in the global market.
MIDV-250 refers to a specific subset or evolutionary stage of the Mobile Identity Document Video (MIDV) family of datasets, which are gold-standard benchmarks for training and evaluating computer vision systems designed to recognize identity documents via smartphones.
Developed by researchers at Smart Engines, this lineage of datasets addresses the critical lack of public, high-quality data for ID recognition due to privacy and security restrictions. Core Context and Purpose
The MIDV series (including MIDV-500, MIDV-2019, and MIDV-2020) provides researchers with "mock" yet realistic documents that feature:
Unique Artificially Generated Data: Names, addresses, and signatures are synthesized to avoid privacy violations.
AI-Generated Faces: Document photos are created using GANs or similar technology so no real persons are depicted.
Diverse Conditions: Captures include high projective distortions, varied lighting, and diverse backgrounds typical of "in-the-wild" smartphone use. Technical Evolution
While "MIDV-250" is often referenced in the context of specific experimental subsets or early iterations of the MIDV-500 project, the lineage has grown significantly:
MIDV-500: The foundational set containing 500 video clips of 50 different document types.
MIDV-2019: An expansion focused on challenging conditions like low light and extreme angles. The MIDV-250 was equipped with a 300-hp diesel
MIDV-2020: The most comprehensive benchmark, featuring 1,000 unique mock documents across video, photos, and high-quality scans. Key Research Applications
These datasets are used to benchmark several critical sub-tasks in identity verification:
Understanding and Analyzing Video Content: MIDV-250
In the vast expanse of digital content, videos play a significant role in shaping perceptions, influencing opinions, and serving as a means of expression. Content like MIDV-250, which might be a specific video or part of a series, underscores the complexity of media in the digital age. Analyzing such content requires a multifaceted approach:
Characteristics
- Transmission: The primary mode of transmission to humans is through contact with infected animals (like pigs) or their products. Human-to-human transmission can also occur, particularly in a hospital setting.
- Symptoms: The virus causes a range of symptoms from asymptomatic infection to acute respiratory syndrome and fatal encephalitis. The symptoms typically begin with a fever, headache, and body aches, progressing to more severe conditions like swelling of the brain (encephalitis) or pneumonia.
- Incubation Period: The incubation period, the time between exposure to the virus and the onset of symptoms, ranges from 5 to 14 days.
Features of MIDV-250
-
Precision Engineering: The MIDV-250 is engineered to deliver high-precision performance, making it an invaluable asset in industries where accuracy is paramount. Its design ensures minimal margin for error, enhancing the quality of output.
-
Advanced Technology Integration: Equipped with the latest technological innovations, the MIDV-250 likely integrates AI, IoT connectivity, and sophisticated algorithms to optimize its operations. This integration enables real-time data analysis, predictive maintenance, and seamless connectivity with other smart devices.
-
Efficiency and Productivity: With its state-of-the-art design, the MIDV-250 aims to significantly boost productivity. It achieves this by automating complex processes, reducing manual intervention, and ensuring continuous operation with minimal downtime.
-
Safety and Reliability: Safety is a critical consideration in the design of the MIDV-250. It incorporates multiple safety features to protect operators and ensure reliable performance under various conditions.
Conclusion
The MIDV-250 strain is part of the Nipah virus family, which poses significant risks to human health due to its zoonotic potential and the severity of the disease it causes. Understanding the virus's characteristics, modes of transmission, and applying preventive measures are crucial to mitigate its impact. Ongoing research aims to fill the gaps in knowledge and to develop effective countermeasures against Nipah virus infections.
(Mobile Identity Document Video-250) is a key dataset in the Mobile Identity Document Video (MIDV) family, specifically designed for advancing computer vision research in automated identity document analysis. While it is a subset or precursor to larger benchmarks like
, it established the foundational framework for capturing identity documents in uncontrolled, real-world mobile environments. КиберЛенинка Overview of MIDV-250
The dataset was created to address the scarcity of public data for ID recognition due to privacy regulations. It utilizes mock documents
with synthetic personal data—including artificially generated faces and text—to ensure privacy compliance while maintaining visual realism. Компьютерная оптика
Title: The Digital Ledger: A Critical Analysis of MIDV-250 and the Evolution of Synthetic Data
Introduction In the rapidly accelerating field of artificial intelligence and computer vision, the adage "data is the new oil" has never been more pertinent. However, unlike oil, data must be refined, structured, and often synthesized to be truly valuable. Within the niche of Document Analysis and Optical Character Recognition (OCR), few datasets have sparked as much technical discussion in recent years as MIDV-250. While its alphanumeric name suggests a sterile industrial code, MIDV-250 represents a significant leap forward in how machines learn to read, interpret, and verify human identity. This essay explores the composition, significance, and broader implications of the MIDV-250 dataset, arguing that it serves as a cornerstone for the next generation of automated document processing.
The Anatomy of the Dataset MIDV-250 (Modern Identity Document Video dataset) is, at its core, a collection of data designed to train AI systems to read identity documents. Comprising 250 video clips of 50 different identity document types from 12 countries, the dataset fills a critical void. Prior to its release, researchers relied heavily on static images or synthetic data that lacked the nuance of real-world interactions.
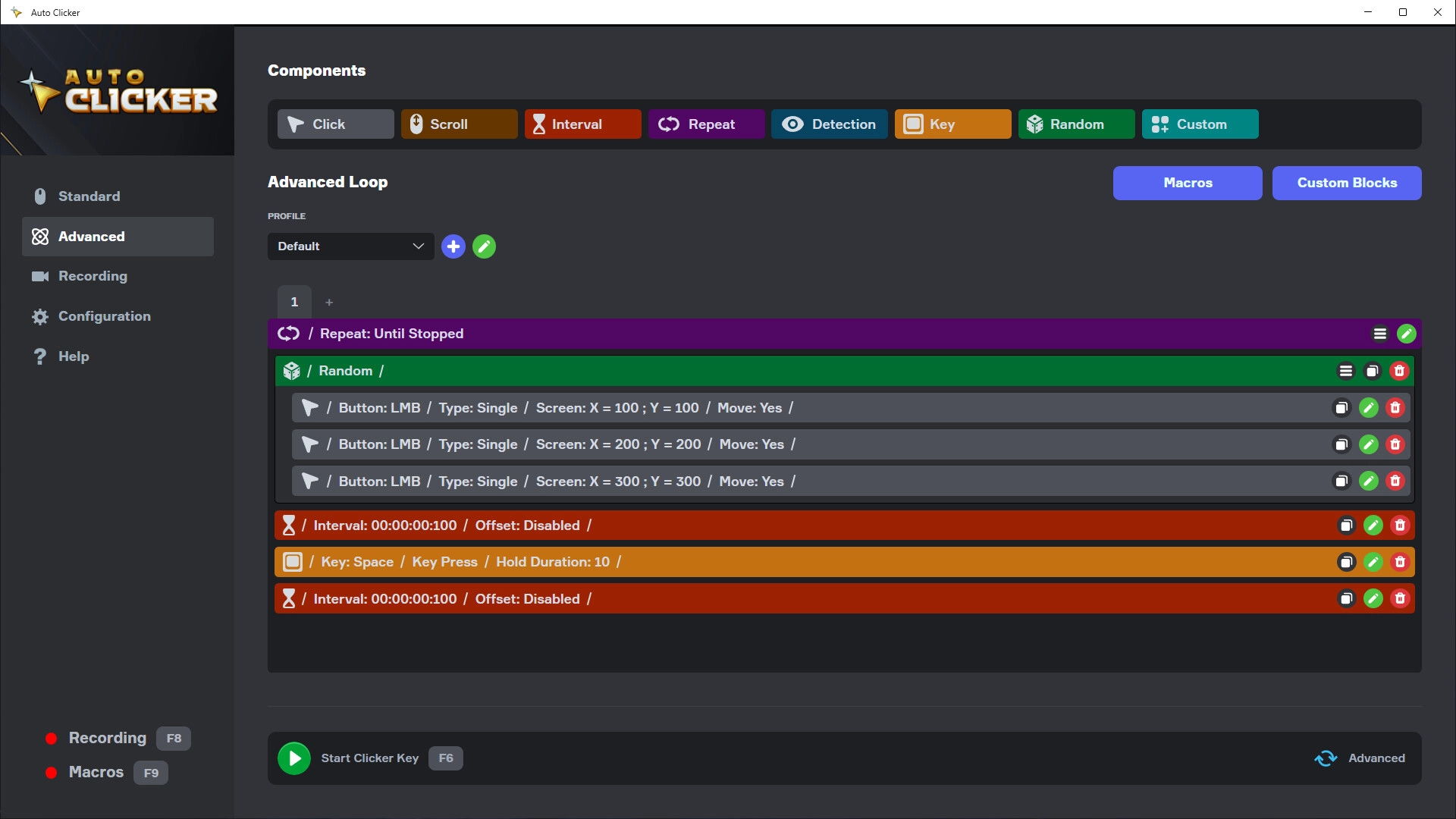
The distinguishing feature of MIDV-250 is its focus on video streams rather than static photographs. In a real-world scenario—such as a user scanning a passport with a banking app—conditions are rarely perfect. There is motion blur, variable lighting, glare, and perspective distortion. By providing video clips, MIDV-250 forces machine learning models to account for temporal consistency and frame-to-frame coherence. It moves the goalpost from simple OCR (reading text) to complex document understanding (processing a moving, imperfect physical object).
Solving the Data Scarcity Paradox One of the most profound contributions of MIDV-250 is its attempt to solve the "data scarcity paradox." Identity documents are, by definition, highly sensitive. Privacy laws such as GDPR and CCPA make it nearly impossible to collect massive, real-world datasets of driver's licenses and passports for public research. This creates a bottleneck: developers need data to build systems, but they cannot legally access that data.
MIDV-250 navigates this ethical minefield through careful curation and the use of documents that are often specimens or created with consent for training purposes. By providing a standardized benchmark, it allows for an "apples-to-apples" comparison of different algorithms. Researchers can finally quantify whether a new neural network architecture is genuinely better at handling motion blur, or if it simply memorized a previous dataset. In doing so, MIDV-250 acts as a "ledger" of truth against which the industry measures progress.
From Extraction to Verification The technical utility of MIDV-250 extends beyond simple text extraction. Earlier datasets focused primarily on the OCR task: locating a name or a date of birth. MIDV-250, however, facilitates the training of models for document layout analysis and fraud detection. Because the dataset includes complex layouts and specific field structures, models trained on it learn the "grammar" of an ID card. They learn where the expiration date should be, or what a specific hologram looks like under different lighting angles.
This shift is crucial for the fintech and security sectors. A system trained on MIDV-250 is not just transcribing text; it is verifying the authenticity of the document structure. This capability is vital in combating the rising tide of digital identity theft, where fraudsters use sophisticated image editing tools to forge documents. The robustness provided by diverse, video-based training data is the primary defense against such synthetic fraud.
Limitations and the Future Despite its utility, MIDV-250 is not without limitations. While 250 clips are substantial for research, they are dwarfed by the millions of images used to train large language models. Furthermore, as document security features evolve, static datasets inevitably become outdated. The very nature of MIDV-250 serves as a reminder that AI development is a continuous race; as detection methods improve, so too do forgery techniques.
Moreover, the dataset highlights the ongoing tension between technical performance and privacy. While MIDV-250 provides a safe harbor for testing, the ultimate deployment of these models often involves handling genuine user data. The ethical framework established by the careful creation of MIDV-250 must be mirrored in the deployment of the technologies it inspires.
Conclusion In the grand narrative of artificial intelligence, MIDV-250 may seem like a minor footnote—a technical dataset read by few and known by even fewer. However, its impact is outsized relative to its obscurity. By providing a realistic, challenging, and ethically curated standard for identity document analysis, it has catalyzed advancements in mobile banking, border control, and digital onboarding. It exemplifies the meticulous, unglamorous work required to bridge the gap between human bureaucratic systems and machine intelligence. As we move toward a future where digital identity is as paramount as physical identity, MIDV-250 stands as a foundational text in the library of machine vision.
Decoding MIDV-250: A Key Resource for Document Analysis and Recognition modes of transmission
In the digital age, the ability of machines to accurately "read" and process identity documents is a cornerstone of modern security, banking, and travel. However, training robust AI models for this task requires high-quality, diverse data. This is where MIDV-250 comes into play.
MIDV-250 (Mobile Identity Document Video dataset) is a specialized dataset designed to push the boundaries of document analysis and recognition (DAR). Below, we explore what makes this dataset unique and why it is vital for researchers and developers. What is MIDV-250?
MIDV-250 is a dataset consisting of video clips and extracted frames of 50 different identity document types. These documents include passports, identity cards, and driving licenses from various countries.
The "250" in its name refers to the total number of video clips provided. Each of the 50 document types is captured in five different environmental conditions, resulting in a total of 250 unique video sequences. Why MIDV-250 Matters
Before datasets like MIDV-250 existed, many document recognition systems were trained on static, high-quality scans. While effective in a controlled office environment, these systems often failed in the real world. MIDV-250 addresses several "in-the-wild" challenges:
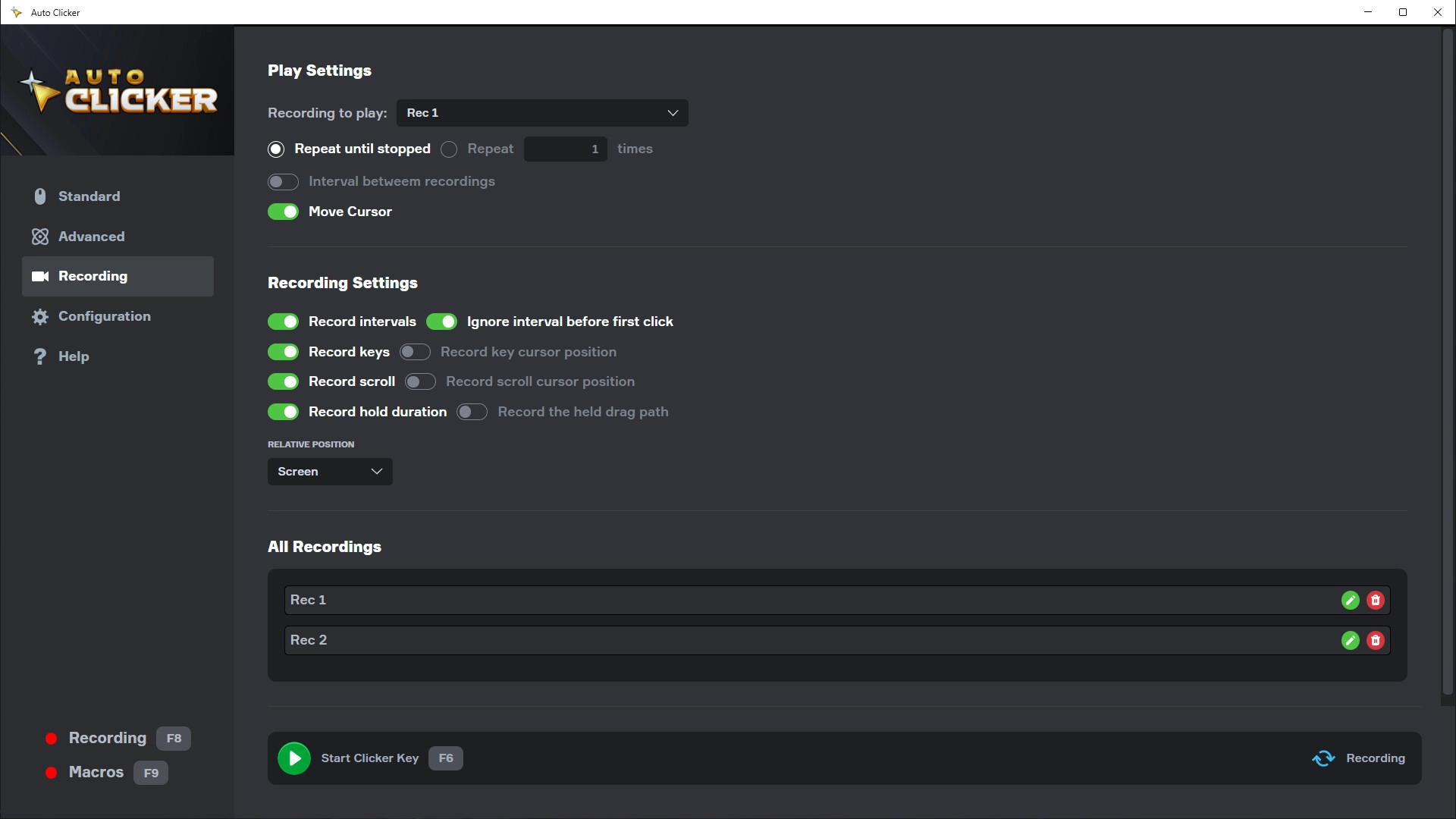
Mobile Capture Simulation: Most people today verify their identity by taking a photo or video with their smartphone. MIDV-250 mimics this by providing data captured via mobile devices.
Environmental Variability: The dataset includes various backgrounds, lighting conditions (glare, shadows), and camera angles. This forces AI models to learn how to distinguish the document from its surroundings.
Distortion Handling: Because the documents are captured in video format, they often feature perspective distortions and motion blur, providing a rigorous test for rectification algorithms. Key Features of the Dataset
Diverse Document Types: It covers a wide range of layouts, fonts, and security features from different nations.
Ground Truth Annotations: Every frame is meticulously annotated with the coordinates of the document's four corners. This is essential for training models to "locate" a card within an image.
Open Access: To foster innovation, MIDV-250 is generally made available for research purposes, allowing the global community to benchmark their OCR (Optical Character Recognition) and document localization algorithms. Applications in Technology The MIDV-250 dataset is primarily used to train and test:
Document Localization: Finding the physical boundaries of a card in a messy environment.
Document Type Identification: Automatically determining if a document is a French ID or a Vietnamese Passport.
OCR Benchmarking: Testing how accurately a system can read text under sub-optimal conditions. Conclusion
MIDV-250 serves as a bridge between laboratory research and real-world application. By providing a standardized, challenging set of data, it enables the development of more reliable ID verification systems that we rely on for everything from opening a bank account to boarding an airplane.
MIDV-250 (Mobile Identity Document Video 2020) is a comprehensive dataset designed to advance the field of automatic mobile document analysis. It specifically addresses the challenges of document recognition and authentication when captured using mobile devices in various real-world conditions. Overview of MIDV-250
The dataset is a sequel and significant expansion of the previous MIDV-500. While the original focused primarily on diverse document types, MIDV-250 shifts its focus toward complex backgrounds and environmental variations to better simulate how users actually take photos of their IDs.
Document Variety: It contains images and video clips of 50 different document types, including passports, ID cards, and driver's licenses from various countries.
Unique Backgrounds: Unlike datasets with plain backgrounds, MIDV-250 features documents placed on five distinct types of surfaces (e.g., table, floor, keyboard) to test the robustness of detection algorithms.
Video-Based: It includes video sequences, allowing researchers to develop methods for multi-frame analysis and tracking, which are more reliable than single-shot recognition in mobile apps. Key Technical Specs Description Total Images 5,000 video frames Document Classes 50 types (International IDs) Capture Devices Modern smartphones with varying camera qualities Primary Goal Document localization, rectification, and text recognition Why It Matters
MIDV-250 is widely used by developers building Know Your Customer (KYC) systems and digital onboarding tools. It provides a standardized benchmark for:
Semantic Segmentation: Distinguishing the document from a cluttered background.
Glint and Shadow Handling: Testing how light reflections on laminated documents affect OCR (Optical Character Recognition).
Low-Light Performance: Evaluating accuracy when the user is in a poorly lit environment.
For more information, the official dataset paper provides in-depth analysis of the baseline results and capture methodology.
Are you planning to use this dataset for training a machine learning model, or AMD BC-250 Gaming PC Case Modification Guide